
Prisma Large Dataset Optimization: Database-Level Strategies for Performance
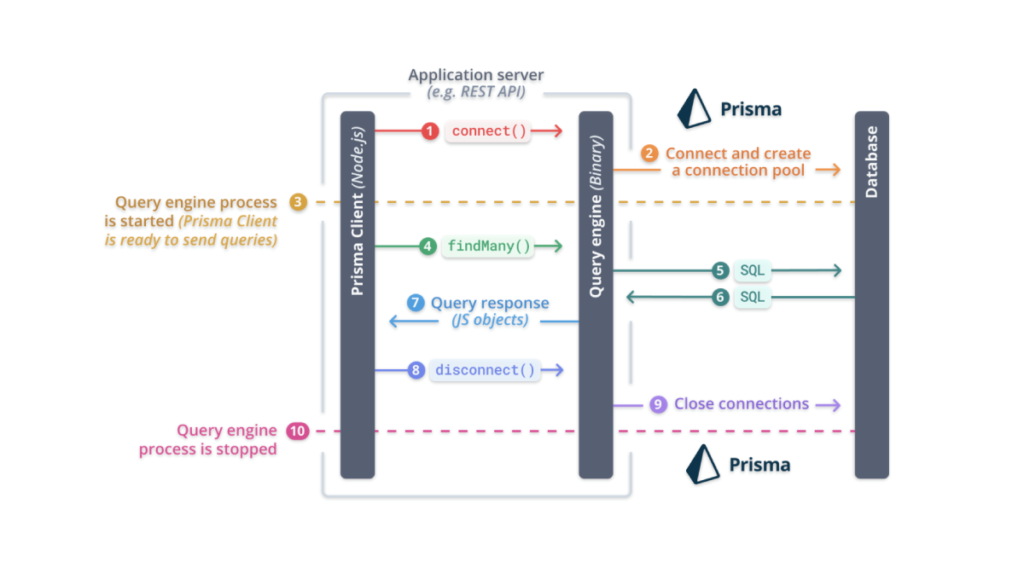
Prisma large dataset optimization is essential for ensuring efficient data handling in modern applications, offering a type-safe and intuitive way to interact with databases. However, as your application scales and data grows, handling large datasets efficiently becomes crucial. Without proper optimizations, Prisma queries—especially findMany—can lead to performance bottlenecks, increased response times, and unnecessary resource consumption.
Table of Contents
Prisma Large Dataset Optimization
Efficiently managing large datasets in Prisma is crucial to maintaining high-performance applications. As datasets grow, inefficient queries can lead to long response times, increased server load, and degraded user experience. To tackle this, optimization strategies must be applied at multiple levels:
1. Optimizing findMany Queries in Prisma
Handling large datasets efficiently in Prisma starts with optimizing the commonly used findMany queries. These queries retrieve multiple records from the database, but without proper optimization, they can lead to performance bottlenecks. Below are key strategies to enhance findMany query efficiency.
Fetch Only Required Fields
By default, Prisma retrieves all fields of a model, even those not required for a specific operation. This increases memory usage and slows down query execution. To optimize, use the select option to fetch only the necessary fields.
Example:
const users = await prisma.user.findMany({
select: {
id: true,
name: true,
email: true,
},
});This ensures that only id, name, and email are retrieved, reducing query processing time.
Use Filtering to Limit Data Retrieval
Instead of fetching all records, always filter data using the where clause. This ensures that only the necessary records are loaded, significantly improving query performance.
Example:
const activeUsers = await prisma.user.findMany({
where: { isActive: true },
});Here, only users with isActive: true are fetched, reducing the dataset size.
Implement Efficient Sorting with Indexing
Sorting large datasets can be slow if the column used in orderBy is not indexed. Make sure to create indexes for frequently sorted fields.
Example: Sorting users by createdAt in descending order:
const sortedUsers = await prisma.user.findMany({
orderBy: { createdAt: 'desc' },
take: 50,
});For better performance, add an index on createdAt in the Prisma schema:
model User {
id Int @id @default(autoincrement())
createdAt DateTime @default(now()) @index
}Limit Query Results Using take
Fetching too many records at once increases memory usage and slows down processing. Always use the take parameter to limit the number of returned records.
Example:
const users = await prisma.user.findMany({
take: 100,
});This retrieves only 100 records, reducing query load.
Use batchSize for Large Queries
For extremely large datasets, retrieving all records at once can overwhelm memory. Instead, break down queries into smaller batches using loops and skip.
Example:
const batchSize = 1000;
let skip = 0;
let usersBatch;
while ((usersBatch = await prisma.user.findMany({ take: batchSize, skip }))) {
if (usersBatch.length === 0) break;
// Process the batch here
console.log(usersBatch);
skip += batchSize;
}This approach fetches records in chunks of 1000, preventing memory overload.
2. Prisma Pagination Best Practices
Efficient pagination is crucial when dealing with large datasets to prevent excessive memory usage and slow response times. Prisma offers two primary pagination methods: offset-based and cursor-based. While offset-based pagination is easier to implement, cursor-based pagination is more efficient for large datasets.
Offset-Based Pagination (Not Recommended for Large Datasets)
Offset pagination uses skip and take to paginate through records. However, as dataset size increases, this approach becomes inefficient because the database must scan and discard skipped rows before returning the requested data.
Example:
const users = await prisma.user.findMany({
skip: 100,
take: 10,
});Drawbacks of Offset Pagination:
- Performance Degradation: The larger the offset, the longer it takes to retrieve results.
- Inefficient for Large Datasets: The database processes and discards skipped rows, leading to unnecessary workload.
- Non-Consistent Results: If new records are inserted during pagination, results may shift and cause duplicates or missing entries.
Cursor-Based Pagination (Recommended for Large Datasets)
Cursor-based pagination (a.k.a. keyset pagination) is a more efficient alternative that avoids scanning skipped rows. Instead, it retrieves results starting from a specified cursor, usually an indexed field such as id or createdAt.
Example:
const users = await prisma.user.findMany({
take: 10,
cursor: { id: lastUserId },
orderBy: { id: 'asc' },
});Benefits of Cursor-Based Pagination:
- Faster Query Execution: Fetches only the required rows instead of scanning and skipping records.
- Scalability: Works well even for datasets with millions of records.
- Consistent Results: Ensures stable pagination without missing or duplicate entries.
Choosing the Right Pagination Strategy
| Criteria | Offset Pagination | Cursor Pagination |
|---|---|---|
| Performance Impact | Slower for large datasets | Faster, even with large datasets |
| Memory Usage | Higher (due to skipped rows) | Lower (fetches only needed data) |
| Complexity | Easier to implement | Slightly more complex (requires a unique cursor field) |
Implementing Cursor-Based Pagination with Composite Keys
For cases where sorting is required on multiple fields (e.g., createdAt and id), use composite cursors to ensure unique ordering.
Example:
const users = await prisma.user.findMany({
take: 10,
cursor: {
createdAt: lastCreatedAt,
id: lastUserId,
},
orderBy: [{ createdAt: 'asc' }, { id: 'asc' }],
});This ensures efficient pagination while maintaining a unique order, even when multiple records have the same createdAt timestamp.
3. Prisma Indexing Strategies
Indexes are a crucial aspect of database performance optimization, especially when working with large datasets in Prisma. Without proper indexing, queries can become slow and inefficient, leading to bottlenecks in your application.
Indexing improves query performance by enabling faster lookups. Consider the following indexing strategies:
Index Frequently Queried Columns
Ensure commonly filtered fields (e.g., email, createdAt) have indexes.
Example:
Adding an index in Prisma Schema:
model User {
id Int @id @default(autoincrement())
email String @unique
createdAt DateTime @default(now()) @index
}This speeds up queries filtering by createdAt.
Composite Indexing for Complex Queries
When filtering by multiple fields, composite indexes enhance performance.
Example:
@@index([status, createdAt])This speeds up queries filtering by status and sorting by createdAt.
4. Using Raw SQL for Performance Optimization
While Prisma ORM is powerful, some complex queries perform better with raw SQL.
Raw SQL for Large Dataset Queries
For optimized querying, use $queryRaw:
Example:
const result = await prisma.$queryRaw`SELECT id, name FROM "User" WHERE active = true LIMIT 100`;This executes a direct SQL query, bypassing Prisma’s abstraction.
Raw SQL for Aggregation Queries
Aggregation queries on large datasets are often inefficient with Prisma’s ORM. Instead, use raw SQL.
Example:
const totalUsers = await prisma.$queryRaw`SELECT COUNT(*) FROM "User" WHERE isActive = true`;This is faster than using Prisma’s count() on large datasets.
5. Optimizing Database Queries in Prisma
Avoid N+1 Query Problem
N+1 queries occur when fetching related records inefficiently.
Bad Practice:
const users = await prisma.user.findMany();
users.forEach(async (user) => {
const posts = await prisma.post.findMany({ where: { userId: user.id } });
});his makes one query per user, leading to slow performance.
Optimized Approach (Using include):
const usersWithPosts = await prisma.user.findMany({
include: { posts: true },
});This retrieves users and their posts in a single query.
Use Database Connection Pooling
For high-traffic applications, enable connection pooling with Prisma Data Proxy or a database connection manager.
Example: In PostgreSQL, enable pooling via pgbouncer.
Conclusion
Handling large datasets in Prisma efficiently requires a combination of database-level optimizations, query tuning, and smart pagination techniques. By implementing these strategies—such as cursor-based pagination, indexing, raw SQL queries, and avoiding N+1 problems—you can significantly improve query performance and application scalability. Additionally, using Prisma Middleware for Soft Deletes can help manage large datasets more effectively by filtering out deleted records at the middleware level. For more detailed documentation on Prisma, visit the official Prisma docs.
By following these best practices, you ensure that Prisma remains a powerful and efficient ORM, even as your data grows. Start optimizing today and experience better performance in your applications!
 Install jsUpskills app on your home screen!
Install jsUpskills app on your home screen!