
Handling Big Data Export to PDF in Node.js: A Scalable Solution

Managing big data export to PDF is a growing challenge for developers building modern web applications. When you’re working with massive datasets, simply generating a PDF isn’t enough—you need a solution that is scalable, efficient, and reliable. This guide explores how to handle big data export in Node.js while maintaining performance and document quality.
We’ll walk you through best practices for exporting large datasets without overloading the server. Learn how to stream data in chunks, avoid memory bottlenecks, and use librarie like PDFKit to create structured, high-quality PDFs.
Perfect for developers building data-intensive applications, this tutorial ensures your PDF exports remain smooth—even when dealing with millions of records. Master big data export in Node.js and deliver performance at scale.
Table of Contents
Why It’s Hard to Big Data Export to PDF
PDF generation libraries like pdfkit, puppeteer, or jspdf work well for small data. But when you’re exporting hundreds of thousands of records, these problems arise:
- High Memory Usage: PDF generation typically happens in memory.
- Timeouts: Synchronous generation blocks the event loop.
- Scalability Issues: You can’t load all data at once.
Our Goal
Create a Node.js service that:
- Handles large datasets (e.g., 100k+ records)
- Streams data in batches
- Generates and streams a PDF file response without crashing the server
Tools We’ll Use
| Tool | Purpose |
|---|---|
pdfkit | PDF creation |
fast-csv | Mock streaming big data |
fs / stream | To manage data efficiently |
express | For the API layer |
Step-by-Step Implementation
1. Install Required Packages
npm init -y
npm install express pdfkit fast-csv faker
2. Setup the Express Server
//app.js
const express = require('express');
const { generatePdfStream } = require('./ pdfGenerator');
const app = express();
app.get('/export-pdf', async (req, res) => {
try {
req.setTimeout(0); // disable timeout
res.setHeader('Content-Type', 'application/pdf');
res.setHeader('Content-Disposition', 'attachment; filename=bigdata.pdf');
await generatePdfStream(res);
} catch (err) {
console.error('Error exporting PDF:', err);
res.status(500).send('Something went wrong');
}
});
app.listen(3000, () => {
console.log('Server running on http://localhost:3000');
});3. Generate Fake Big Data (Simulating DB)
// dataGenerator.js
const faker = require('faker');
function* generateFakeUsers(count = 100000) {
for (let i = 0; i < count; i++) {
yield {
id: i + 1,
name: faker.name.findName(),
email: faker.internet.email(),
city: faker.address.city(),
};
}
}
module.exports = { generateFakeUsers };4. Create the PDF Stream Generator
// pdfGenerator.js
const PDFDocument = require('pdfkit');
const { generateFakeUsers } = require('./dataGenerator');
async function generatePdfStream(outputStream) {
const doc = new PDFDocument({ margin: 30, size: 'A4', autoFirstPage: true });
// Pipe PDF to output stream (res object)
doc.pipe(outputStream);
doc.fontSize(20).text('User Data Export', { align: 'center' });
doc.moveDown();
doc.fontSize(12).text('ID | Name | Email | City');
doc.moveDown(0.5);
const MAX_ROWS = 50000; // You can tweak this
let rowCount = 0;
for (const user of generateFakeUsers()) {
const row = `${user.id} | ${user.name} | ${user.email} | ${user.city}`;
doc.text(row);
rowCount++;
if (rowCount % MAX_ROWS === 0) {
// Optional: Flush to disk or monitor memory here
await new Promise((resolve) => setImmediate(resolve)); // Yield
}
if (doc.y > doc.page.height - 50) {
doc.addPage();
}
}
doc.on('error', (err) => {
console.error('PDF Error:', err);
});
doc.on('finish', () => {
console.log('PDF writing done!');
});
doc.end(); // Finalize the PDF stream
}
module.exports = { generatePdfStream };
5. Testing the Endpoint
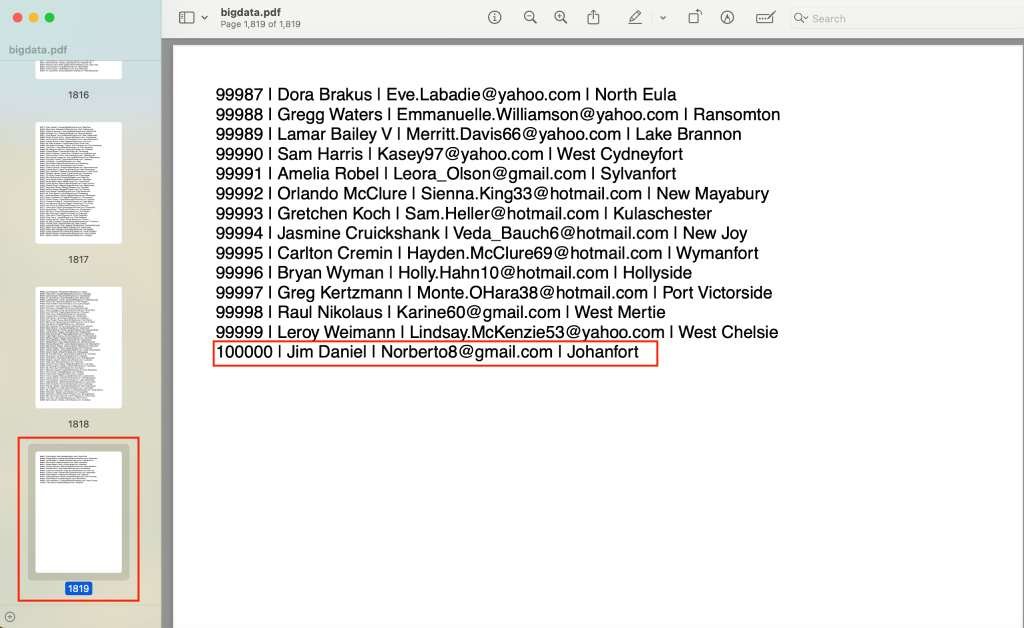
node server.jsOpen browser or Postman:
http://localhost:3000/export-pdf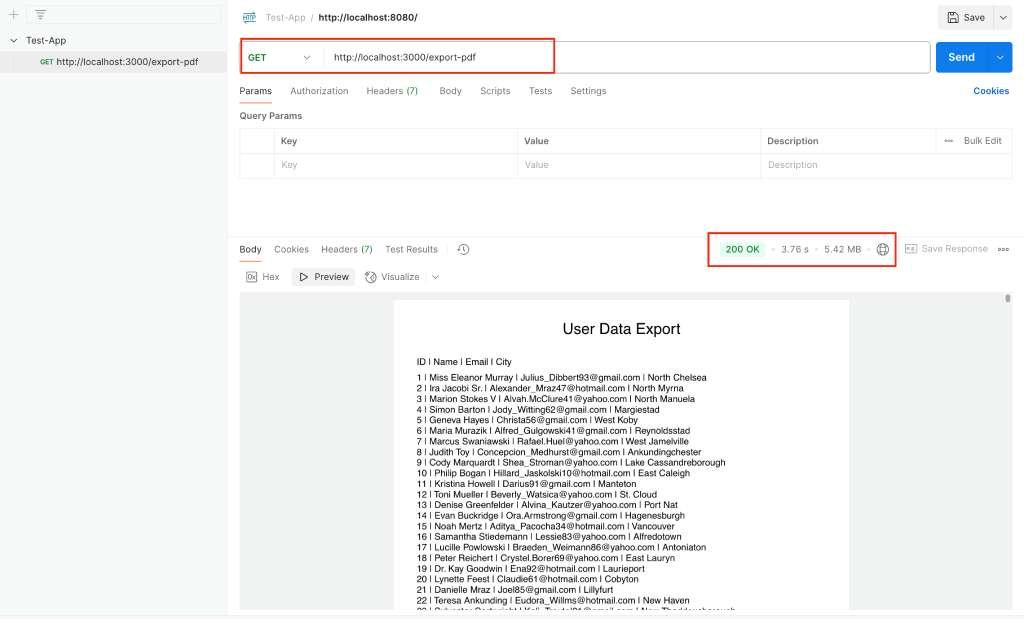
Pro Tips
- Use database cursors instead of in-memory fake data in production.
- Consider using pagination with offsets or keyset for consistent exports.
- For better layout, integrate
pdfkit-table.
Conclusion
Big data export to PDF in Node.js is not only possible—it’s efficient when built with the right architecture. Using PDFKit, you can generate well-structured PDF documents while handling massive datasets smoothly. The key is to process data incrementally through streaming and batching, which prevents memory overload and ensures stable performance. Instead of loading everything at once, stream your content intelligently and build your PDF output as data flows. This approach allows your application to scale seamlessly and remain responsive under heavy data loads. With PDFKit and a smart export strategy, you’re well-equipped to turn complex data into professional, high-volume PDF reports. For more tips on securing your Node.js applications while handling large data, check out this guide on fixing Node.js security vulnerabilities.
Project Source Code
If you’d like to see the full implementation of this solution in action, check out the GitHub repository:
Big Data Export to PDF using PDFKit (GitHub)
This open-source project includes:
- Full Node.js backend code with PDFKit
- Streaming and batching logic for large datasets
- Memory-efficient data handling
- Sample dataset for testing
- Step-by-step documentation
git clone https://github.com/jsupskills/Big-Data-Export-to-PDF.git
cd Big-Data-Export-to-PDF
npm install
node index.js
Refer to the README.md for detailed usage instructions and customization tips.
 Install jsUpskills app on your home screen!
Install jsUpskills app on your home screen!